


搜索到
141
篇与
软件类
的结果
-
 傻瓜式一键生成专业级混剪卡点视频 傻瓜式一键生成专业级混剪卡点视频 本帖为炫耀贴 不提供软件下载 也不开源 主要功能 按照用户上传的音频文件,自动检测鼓点(可以大范围微调鼓点检测灵敏度) 并且根据鼓点自动卡点 支持纯图片合成卡点视频 支持纯视频合成卡点视频 支持图片和视频混合卡点视频 自动检测目标文件夹内的第一个文件 横版竖版以及分辨率等等 自动去开头结尾音频静音部分 高级素材复用算法 精细鼓点微调算法 界面简单,功能强大 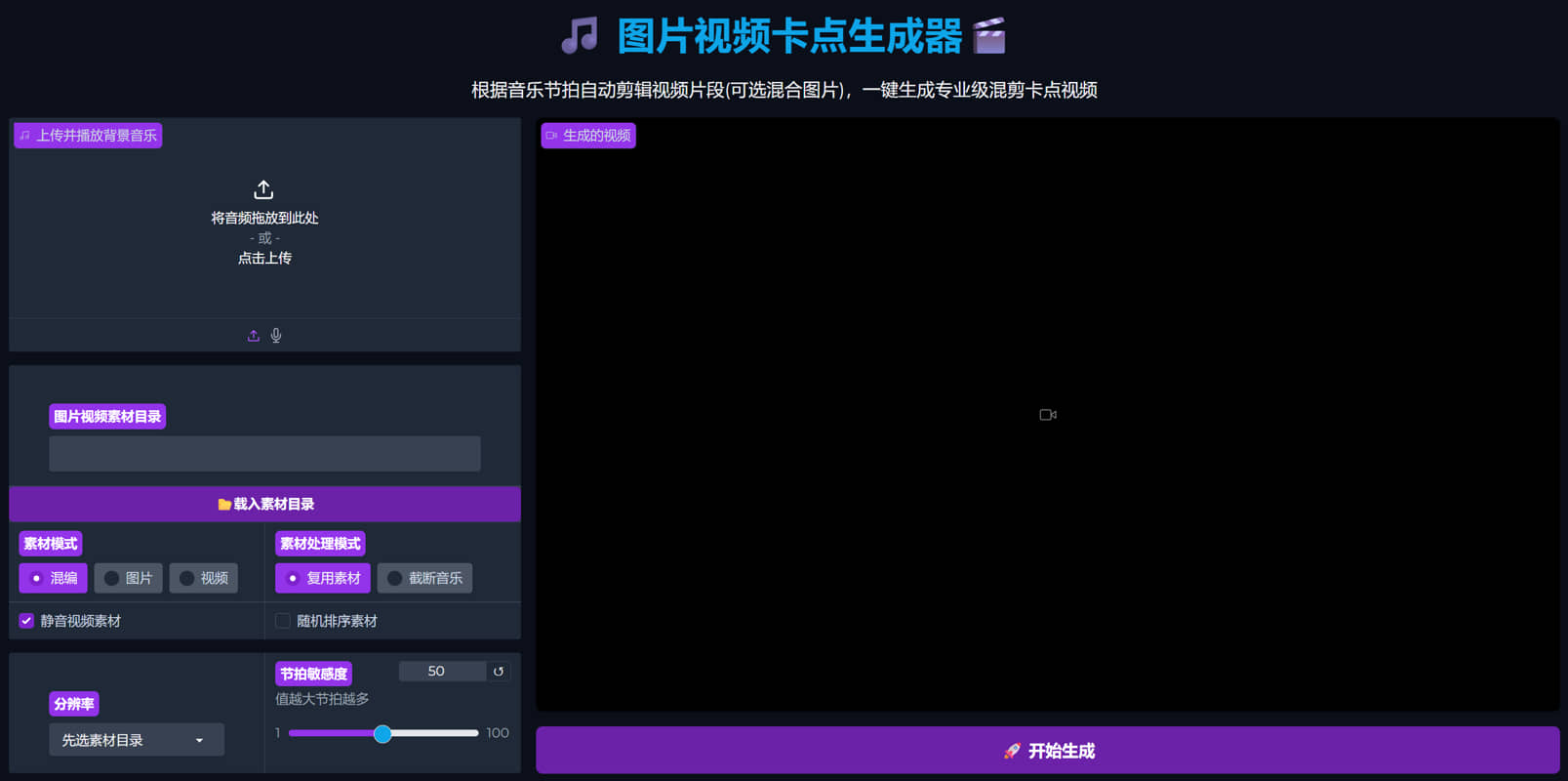 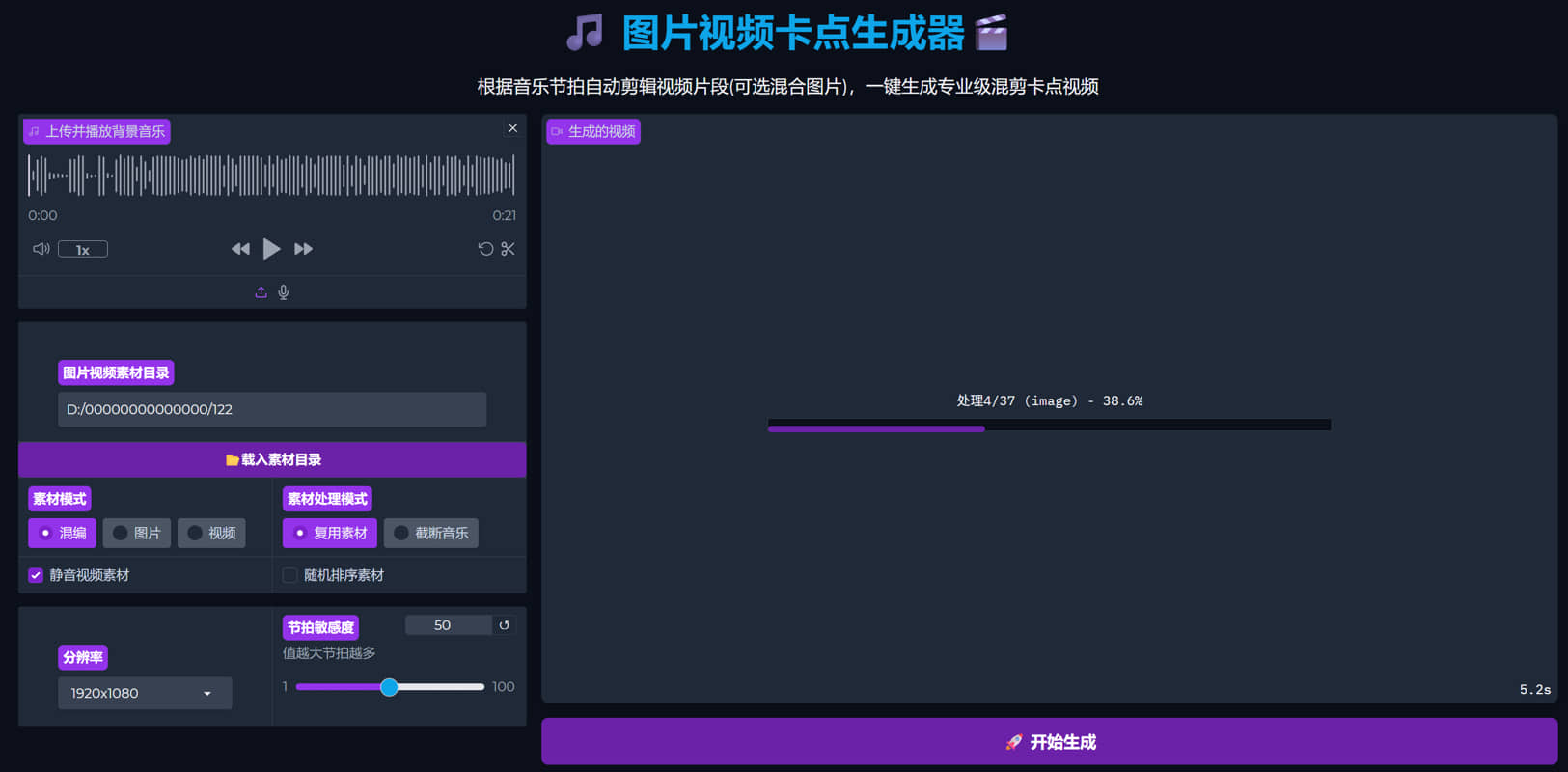 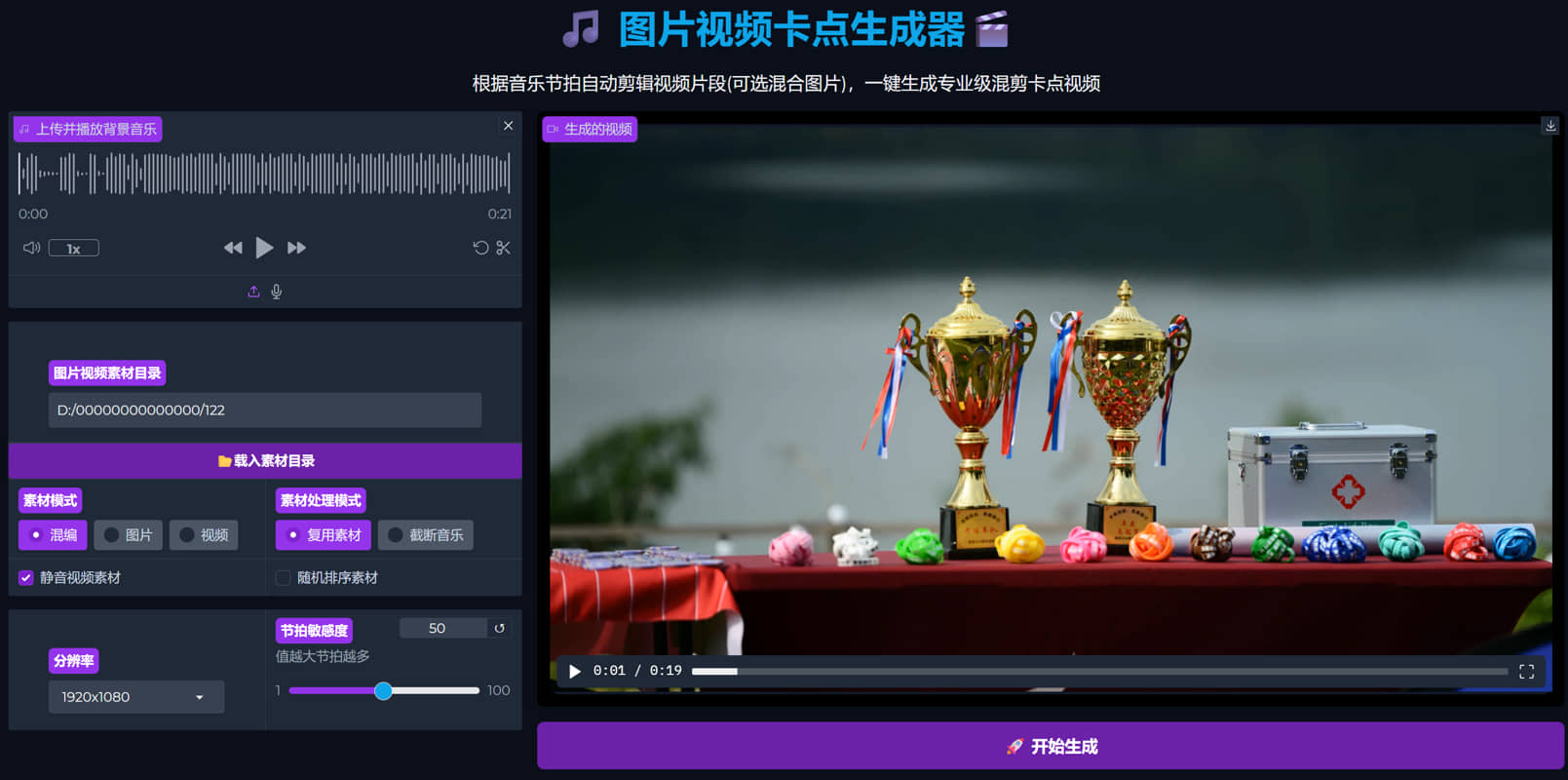
傻瓜式一键生成专业级混剪卡点视频 傻瓜式一键生成专业级混剪卡点视频 本帖为炫耀贴 不提供软件下载 也不开源 主要功能 按照用户上传的音频文件,自动检测鼓点(可以大范围微调鼓点检测灵敏度) 并且根据鼓点自动卡点 支持纯图片合成卡点视频 支持纯视频合成卡点视频 支持图片和视频混合卡点视频 自动检测目标文件夹内的第一个文件 横版竖版以及分辨率等等 自动去开头结尾音频静音部分 高级素材复用算法 精细鼓点微调算法 界面简单,功能强大    -
图片加音乐转视频,傻瓜卡点神器V2.9 图片加音乐转视频,傻瓜卡点神器(非免费,打赏多少随意) 未注册也能用,但是限制输出前10秒 可以直接将你的注册码回帖给我,请使用正确的邮箱 一开始请使用较短音频文件测试,例如十几秒30秒内的 之后再用整首歌音频 长音频拆解鼓点效率较低,更改节拍节奏参数后可能会卡顿假死 简介: “图片加音乐转视频,傻瓜卡点神器”是一款专为视频创作者设计的工具,旨在简化将图片和音乐结合生成视频的过程。这款工具特别适合那些在视频编辑软件中进行卡点操作时感到困难的用户。它提供了一种简单、直观的方式来创建具有音乐节奏的视频,无需复杂的编辑技巧。 功能特点: 时长控制:用户可以根据音频的长度和可用图片的数量,灵活控制视频的时长。如果音频时间较长而图片数量不足,可以选择重复使用图片以填满视频时长。 截断音乐:如果图片数量有限,可以选择在图片用完时截断音乐,确保视频内容与图片匹配。 图片顺序:默认情况下,图片会按照文件名排序进行播放,但用户也可以选择随机顺序,为视频增添更多创意。 节拍节奏:提供了“舒缓”和“激进”两种节拍节奏选项。舒缓模式会过滤掉鼓点不明显的节点,适合图片数量较少的情况;激进模式则会包含更多鼓点,即使鼓点不明显也会进行节点切换,适合图片数量较多的情况。 自适应图片大小:工具会自动检测图片的大小,并根据目标分辨率进行自适应调整。如果图片小于目标分辨率,工具会自动缩放拉伸。最好能提前裁剪好16:9,否则会有变形. 支持多种文件格式:除了支持图片文件,还支持直接使用MP4作为音频文件,增加了工具的灵活性。 卡点精度:随着版本更新,卡点的准确性得到了提升,确保视频中的图片切换与音乐节奏更加匹配。 使用方法: 下载与安装:用户可以通过提供的链接下载工具,双击运行,注册后需要重新运行生效。 加载图片和音乐:将准备好的图片放入指定文件夹,并选择相应的音乐文件。 设置参数:根据需要设置视频的时长、图片顺序、节拍节奏等参数。 生成视频:点击生成按钮,工具将自动处理图片和音乐,生成最终的视频文件。 注意事项: 联网验证:该工具需要联网验证注册码,因此需要确保网络连接正常。 注册与打赏:虽然工具不是免费的,但用户可以根据自己的意愿进行打赏。打赏并不意味着买断或拥有所有权。 服务器限制:由于使用了公网服务器,可能会受到政策等因素的影响,导致服务不可用。 本地离线版本:如果用户有需求,开发者可以提供本地离线版本,但可能需要额外的赞助。 示例与下载: 示例视频:开发者提供了使用该工具生成的视频示例,用户可以通过链接查看效果。 下载链接:工具的下载链接和提取密码也已提供,方便用户获取和使用。 总的来说,“图片加音乐转视频,傻瓜卡点神器”是一款功能强大且易于使用的工具,适合视频创作者快速生成具有音乐节奏的视频内容。 已知问题,长音频文件,载入后波形图有点卡,这个暂时没办法优化,因为同时分析音频鼓点,生成波形图鼓点图等等 PY写的程序,对中文支持一向不友好 文件夹路径,文件名,最好都不要有中文,以及符号等等 这个是常识,不要问这种蠢问题,不是我的问题,不是软件问题 启动慢,不是软件问题,高压打包成单文件,解压有个过程,看你电脑情况,后续可能会提供一个不打包的版本 不要一直问这问那,我写软件都是按照用户是猪写的,没有骂你的意思,我也是用户 没有比这个软件使用更简单的了 我告诉你已经注册了,或者是好了 那说明你注册码已经生效了 你重新启动程序即可 某些所谓原装系统可能需要以管理员身份运行,我电脑不用,我测试的电脑都不用 标准图片16:9,不符合要求的会拉伸,如果不想生成视频变形,请自行裁剪好 不要一直问重复的问题,软件基本功能都是以符合我自身所需开发的 至于定制某个特定功能,那是榜一大哥才有的特权 **没有售后,非必要请勿加好友** 关于转换效率,所有设置均默认,3分钟MP3文件,转换完成耗时约2分钟,效率还是很不错的 更新,自适应图片大小,旧版如果图片小于目标分辨率会报错,大于目标分辨率会截取中间部分 另外,如果你载入的图片文件夹,第一张图片是横版,其他都是竖版,则按照第一张图片输出横版!!! 请手动将横版竖版分开放在不同文件夹 后续有可能会自动筛选横竖版 版本更新,去掉了横竖选项,检测图片自适应 版本更新,增加拉伸自适应 版本更新,支持直接使用MP4作为音频文件 版本更新,卡点更准 版本更新,载入音乐时,会计算所需图片,切换节拍节奏时,会计算所需图片 版本更新,界面重构 版本更新,载入音乐后,会显示波形鼓点图 版本更新,按空格会播放你载入的音乐,再按暂停,再按继续播放 版本更新,可视化进度显示 版本更新,关闭后清理后台 版本更新,未注册也能用,但是限制输出前10秒,且不显示波形鼓点图,所有设置均为默认设置,不可更改,注册后解锁 版本更新,支持本地验证,无需联网即可使用,绑定CPU,不换CPU情况下,随便重装系统都不会失效 (如需本地授权,可以先试试在线的是否可以满足使用需求,本地授权后不会退费) 版本更新,波形图支持鼠标滚轮缩放,左键按住拖拽 版本更新,节拍节奏可以自行微调,以适应不同节奏音乐卡点,数值越小,卡点节拍越多,数值越大,会跳过鼓点不明显的节拍,默认0.2,已适合大部分鼓点清晰的音乐 版本更新,优化波形图生成效率,虽然还是很低... 不再提供旧版,仅提供新版,之前已打赏的,可以将注册码给我,直接升级到新版 以下是本工具转换的视频例子 旧版生成的,与新版大差不差 [https://tuchong.com/1618660/video/11395326/share](https://tuchong.com/1618660/video/11395326/share) 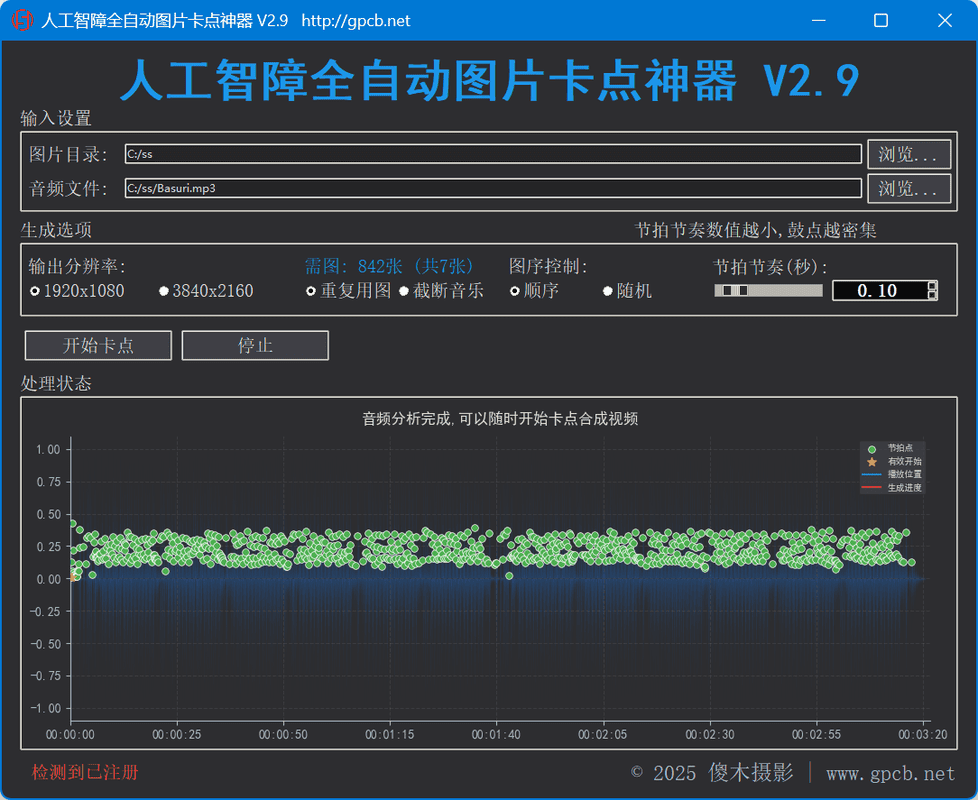
-
全自动视频卡点 全自动视频卡点 非免费 随意打赏后将注册码发给我 部分电脑无法获得硬件码,无法注册,这个暂时不清楚什么情况 可以下载这个工具进行视频预分割之后,再卡点 [https://gpcb.net/5685.html](https://gpcb.net/5685.html) 运行界面 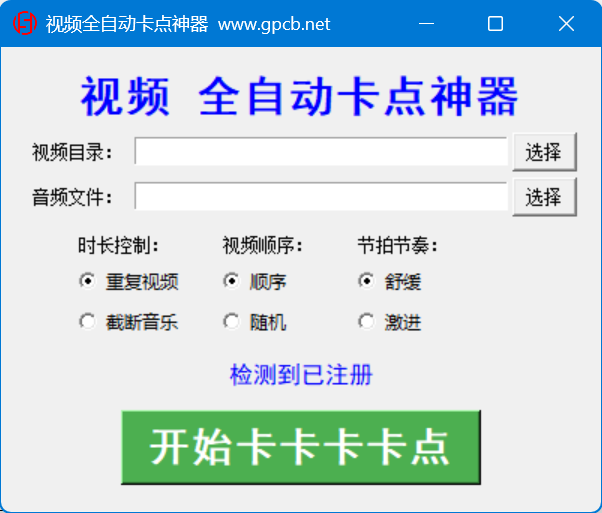 时长控制,如果音频时间较长,视频片段少 可以选择重复视频,即,如果一分钟需要120段视频,但是你只有100段,那么会重复使用其中20段视频 截断音乐,即,视频用完即止 视频顺序,默认按照文件名排序 可以选择随机乱序 节拍节奏,默认舒缓,即,过滤掉鼓点不明显的节点(相对视频需求少些) 激进,鼓点不明显的也会做节点(相对视频用的多些),鼓点多,换视频多,可能会晃眼,不明显的也换换,可能效果不太好 说明,这个需要联网验证是否注册 至于你注册打赏多少,随意即可 打赏了,不表示买断,不表示你拥有所有权 还有很多不足之处,只能慢慢改,打赏了你提了要求也不一定能做到 注册时,我需要将你注册码写到我服务器,可能你有时间我没时间,急用的请勿打赏 由于是公网服务器,受限于政策原因,可能随时不可用,这个不可控 如果你有票子,可以赞助一下,给你单独做个本地离线的 支持直接使用MP4作为音频文件 载入音乐时,会计算所需视频片段,切换节拍节奏时,会计算所需视频片段 由于bug,暂停下载,尚在修bug中
-
视频自动分割分镜工具 视频自动分割分镜工具 这是一款名为“视频自动分割(分镜)工具”的桌面应用程序,基于Python和PyQt5开发。 它的主要功能是自动分割视频文件或文件夹中的视频,通过检测画面变化来分割视频片段。 程序具备直观的图形用户界面,支持多种视频格式,提供画面检测阈值设置功能,允许用户调整检测的敏感度。 用户可以一键选择视频文件或文件夹,指定输出目录后开始分割视频,分割完成后还可以一键打开输出目录查看结果。 该工具适用于需要对视频进行快速自动分割的用户。 本工具为后续视频自动卡点做辅助 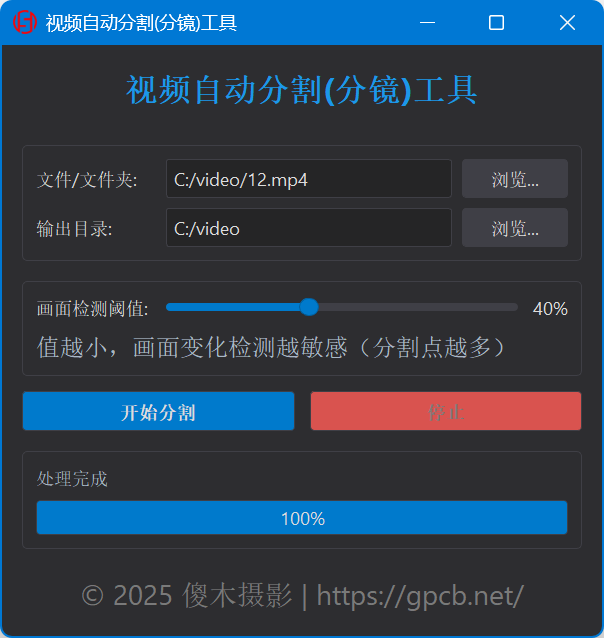 无功能限制,无广告,无套路,免费 用爱发电,欢迎打赏  [https://abpyu.lanzoul.com/i7REh2xk293a](https://abpyu.lanzoul.com/i7REh2xk293a) 密码:6b8q
-
waiNSFWIllustrious_AI生成动漫图片整合包,12G英伟达显卡即可愉快玩耍 初始化模型载入需要8gb显存,之后分解关键词等等子模型运行后总共需要消耗约12gb显存 本工具主要用来生成动漫效果 输入关键词,点击生成即可 底下有高级设置,分辨率和步骤等  jian27打包分享 [https://www.jian27.com/html/2046.html](https://www.jian27.com/html/2046.html) 本站在上述基础做了负优化 主要就是减肥,原包13gb,现在8gb 仅提供百度网盘连接 回复后,刷新可见 隐藏内容,请前往内页查看详情
-
IndexTTS: 可控高效语音合成系统,一键懒人包,自媒体配音神器 IndexTTS: 可控高效语音合成系统,一键懒人包,自媒体配音神器 之前测试过好几个类似的软件 都没有这个好,可以听听下面这段音频,停顿以及语气,是不是与原装无异? 本站不是什么正经网站,我也不是什么正经人,你也不用一本正经的全都看完。本站发布的软件使用起来都是及其简单,饭盛碗里递你手上了,筷子递你手上了,怒不提供喂饭服务,不会用也不用留言问,请自己琢磨研究。实在不会用,请删除。看见官方有更新的,也不用催更,只做我想做的。 本站是我私人的自留地,我所说的都是我想说的,合法且不会触及我的道德底线。如果触及了你的心理防线,我建议你将这条线拉高一点。如果你是我同事,看见了你不想看见的内容,请你装作没看见,也不用给我留言。这是我唯一可以肆无忌惮倾诉的地方,请给我留一条活路! 默认是静音的,点下喇叭图标开启 [影音片段: 请查看原文播放] jian27打包,更新地址 https://www.jian27.com/html/624.html 在他打包基础上,本站进行了负优化 减少了体积,压缩包原先4.6gb,负优化后4.2gb 原先输出wav音频格式,已改成MP3 简化了目录结构,原先目录较乱,现在目录结构如下  还有其他一些优化 本工具如果用来转换大段文本,效率是比其他软件低很多的 原因是本软件拆字断句与其他软件截然不同,本软件几乎是逐字拆句的 好在最终效果比其他软件输出的效果好 例如千字左右段落约需要4分钟左右 占用显存7gb左右 百度网盘,回复后刷新可见 隐藏内容,请前往内页查看详情
-
DeepSeek本地部署一键运行DeepSeek-tool v10+Qwen3-30B-A3B DeepSeek本地部署一键运行DeepSeek-tool v10+Qwen3-30B-A3B Qwen3前几天发布了 群里打包了懒人包 升级了llama,我替换了模型 内置的模型只有一个Qwen3-30B-A3B 需要12gb黄皮显卡 少于12gb的可以下载jian27版本 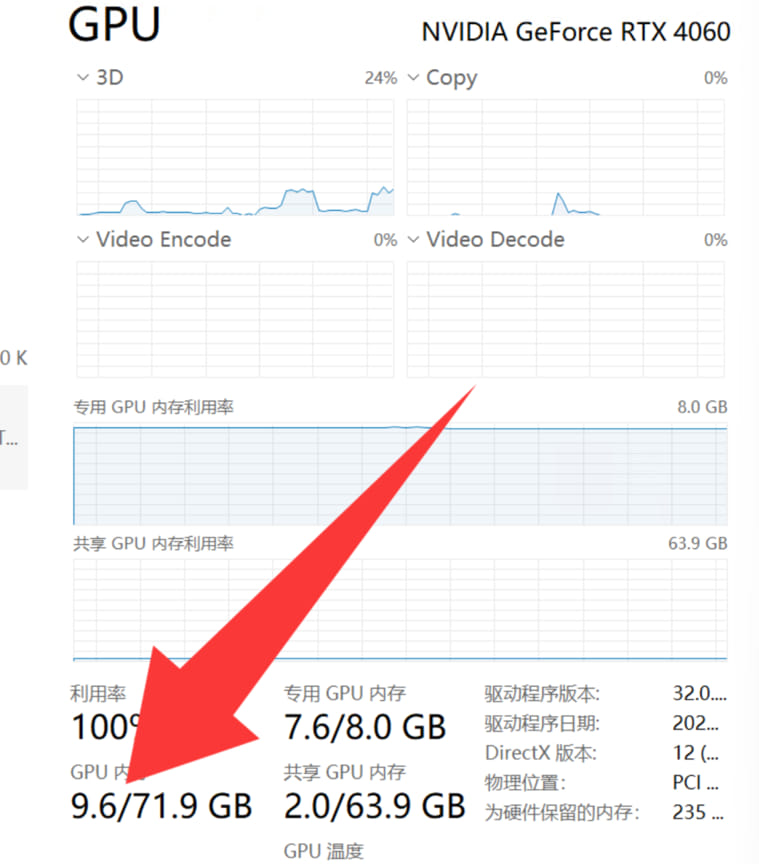 默认的管理员账号是jian27@126.com 和123@123.com 密码1234 进去后 自行修改 [转载自jian27 ](https://www.jian27.com/html/1396.html) 百度网盘下载链接,回复后刷新可见 11.95gb 隐藏内容,请前往内页查看详情







网站版权本人所有,你要有本事,盗版不究。 sam@gpcb.net